lava's render engine (namely magma) is meant to be recent standards efficient and, secondly, innovant. For the end-user, the renderer details are completly hidden. This small article explains what's behind an experimental renderer: the deep-deferred render.
The problem with current renderers
About classic forward renderer
Nowadays, mainly in VR and mobiles, a forward renderer is used. It is the straightforward way to handle the problem: I have some geometry, I'm going to draw it on screen.
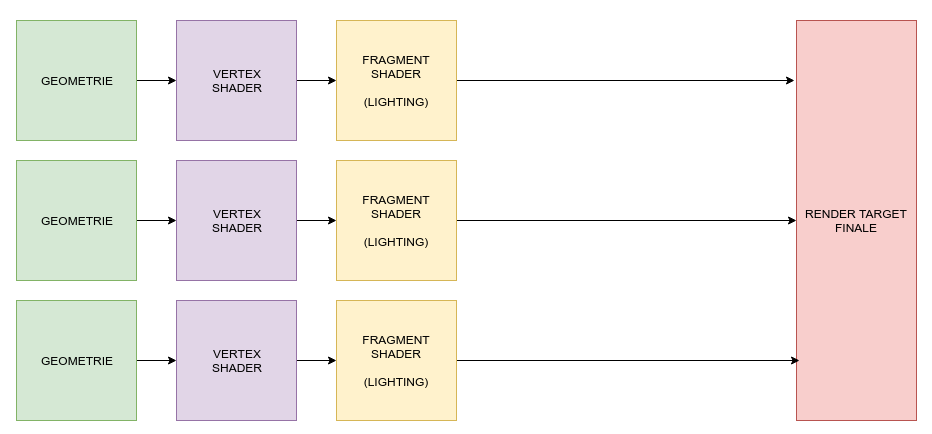
To show what's in front of everything, people uses depth maps, but everything is illuminated, even if it not shown. So that, if you want multiple lights in your scene, making complex computations for each one on each fragment, you can spend a lot of time for something that won't even be visible.
One way to go is to sort your meshes from the front-most to back-most ones.
About classic deferred renderer
On PC and modern consoles, people started to think and tried some other methods, allowing us not to sort the meshes and possibly get improved performances. The way to go is called a deferred renderer.
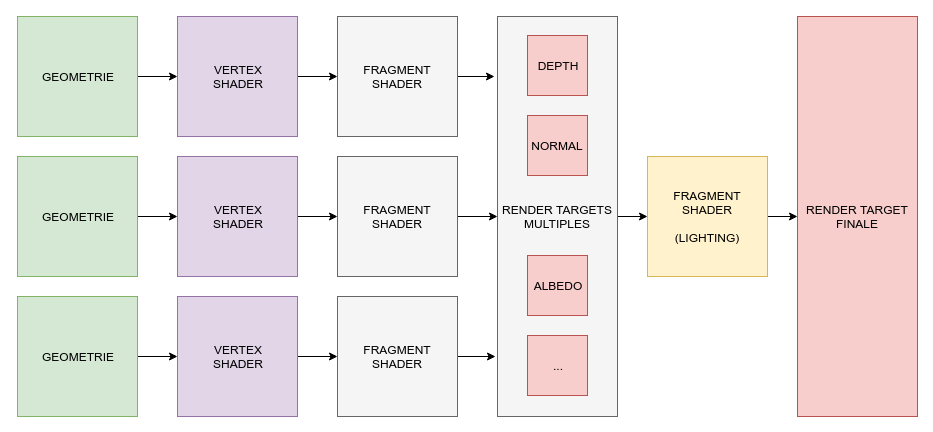
The idea is to store everything you use to compute the lighting in different render targets. That way you will have to do the complex computation only once per pixel at most.
 On the left, all three textures used to store information about the formost fragment (normal, depth and position). On the right, the final result with multiple light sources. Source: wikimedia
On the left, all three textures used to store information about the formost fragment (normal, depth and position). On the right, the final result with multiple light sources. Source: wikimedia
The main drawback is memory. This costs a lot of memory. Current generation of GPUs seems to be ok with that, but, hey.
Translucent materials - ouch!
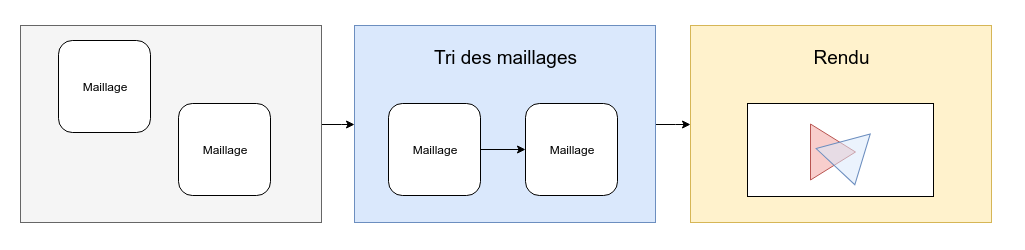
Translucents materials needs to be ordered, as the final color depends on what's in front.
![]() Your brain should be able to sort out which square is in front in both cases.
Your brain should be able to sort out which square is in front in both cases.
For the forward renderer, one can simply sort the meshes before rendering.
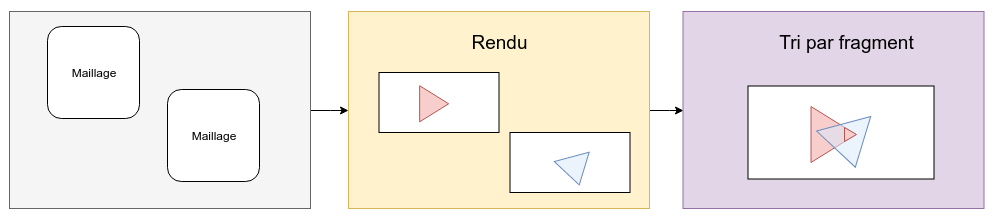
For the deferred renderer, it is strictly impossible. The classic approach is to use a forward renderer in combination with a deferred one, just to handle translucent meshes independently.
BUT there is one problem with sorting meshes. It cannot render correctly is meshes intersect.
![]() On the left, only the red plane is translucent. On the right, both. This screenshot was taken within Unity Engine.
On the left, only the red plane is translucent. On the right, both. This screenshot was taken within Unity Engine.
As the blue plane has been computed to be the closest to the camera, it is rendered in front. There is no way to stop that. Or, maybe, you can cut the red plane in half, but that will add a draw call, and is surely not fun if you have a thousand of those.
→ What I tried in lava is a way to answer the question: how to prevent that?
Deep deferred renderer
The method I will expose is what I call a deep-deferred renderer.
What we should keep
We know that the design of the deferred renderer is efficient, and that sorting is required whatever happens.
But, somehow, it feels strange to sort meshes, when, maybe, only a subpart of the material is transparent, like the windows of a car. Moreover, the classic way to store G-Buffer into different render targets feels clumsy.
→ Having all that in mind: What if we sort things at the pixel level?
Implementation
We want to sort translucent fragments at the last possible moment.
One idea is to store everything within a GPU linked list.
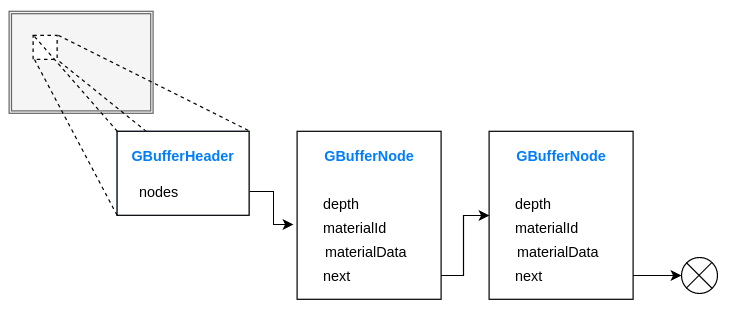
As allocating on the fly won't mean anything in a GPU context, we pre-allocate a large block of memory. This is called a SSBO (Shader Storage Buffer Object), which is contiguous memory.
We could use render targets as in a classic deferred renderer, but that would be a nightmare. Here, a pointer to the next node of our linked list is just an index in a big array.
layout(std430, set = 1, binding = 0) buffer GBufferHeader {
uint width;
uint listIndex[];
} gBufferHeader;
struct GBufferNode {
uint materialId6_next26;
float depth;
uint materialData[GBUFFER_MATERIALDATA_SIZE];
};
layout(std430, set = 1, binding = 1) buffer GBufferList {
uint counter;
GBufferNode nodes[];
} gBufferList;
Define (in glsl) the header and the list as SSBOs.
Moreover, SSBO ensures us atomic writing and reading.
Memory issue
For a simple PBR material:
depth(4 bytes) ;materialId(4 bytes) ;next(4 bytes) ;opacity(1 bytes) ;albedo(3 bytes) ;normal(3 bytes) ;occlusion(1 bytes) ;roughness(1 bytes) ;metallic(1 bytes).
Which means 21 bytes per GBufferNode.
So for rendering a 1920x1080 image with 3 levels of translucency, at the worst case:

Memory issue optimisation
By being a bit clever, storing normal on two floats, combining materialId and next on the same uint, and such. We can go down to 71 MB.
As a comparison, one render target (1920x1080) with 5 channels is 8 MB, and a classic deferred renderer has around 4 render targets.
SSBO vs. Render targets
Sadly though, we can't use just SSBOs, as they induce too much concurrency issues for opaque fragments.
So some GBufferNodes are still stored in render targets.
Concurrency issue with opaque fragments testing depth.
It works!
Whatever concessions we had to make, it works!
And to sum up everything…
Pros:
- As interesting as classic deferred renderer ;
- Post-processes more powerful, as they can use the G-Buffer information of translucent fragments ;
- Only one geometry draw ;
- Materials decide if they are opaque or translucent at fragment level.
Cons:
- Harder to debug (due to SSBOs);
- Costly (memory-wise) pour extreme cases;
- Two data structures needed (might be fixable).